As well as the 32bit rpm version of the Linux client, Juniper have a browser based Java applet for all OSes – which also works on Linux.
It’s not as pretty as the windows/mac client, but it can be made to work – and if you rummage around in it enough it contains a non-java executable at its core which may be useful as the basis of a homebrew non-java application.
Caveats:
This blog post describes a way to get connected to the new UoB vpn using a linux client. It’s not tested enough, or foolproof enough to qualify as “official” documentation. It’s more a record of “what I did to make it work”.
We’ve still got a fair way to go before we can publish any of this fully alongside the other instructions.
So try it, if it works for you great! Let us know in the comments! If I’ve got something wrong, or you’ve worked around one of the problems I hit, let us know in the comments!
If it doesn’t work for you we’d like to hear about that too, but asking for help via the bris-linux mailing list or the IRC channel is probably going to be more productive than asking in the comments.
Ubuntu 12.04 and 12.10 (64bit)
The GUI for the vpn client is a 32bit Java application. Ubuntu doesn’t appear to install java at all as part of the base install. So if you’re starting from a point where you have no java support at all, it’s fairly straight forward:
sudo apt-get install icedtea-7-plugin openjdk-7-jre:i386
The icedtea-7-plugin package will pull in the 64bit version of Java as a dependency, and the 64bit version is chosen by preference. You can change this by running:
sudo update-alternatives --config java
And select the 32bit version from the list.
At this point, you’ve got 32bit java installed and selected as your default version of java. You also have the icedtea java plugin for 64bit web browsers installed.
Now point your web browser at https://uobnet.bris.ac.uk and sign in using your UoB username and password. When the page loads, you should see a line which says “Network Connect” – click the Start button.
You’ll probably get a popup warning saying that you need to make sure you’ve got all the required 32bit libraries installed. You have (we’ve just done that!) so click “Yes” – you’ll also get a couple of popups asking if you’re sure you trust the certificate the application was signed with
The first time you run Network Connect it will pop up a terminal window and ask you to put in your (local) sudo password. This is because the underlying vpn widget needs to run as root, and this popup will setuid the binary so you don’t need to sudo every time you connect.
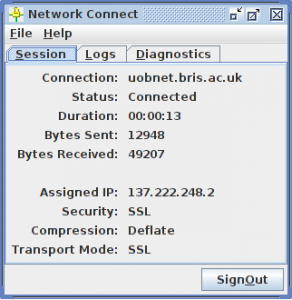
With a bit of luck and a following wind, you’ll get an ugly box pop up which says you’re connected!
Fedora/RedHat/CentOS/ScientificLinux
I haven’t tested any of these, but as far as I can tell, doing this would probably work:
sudo yum install java-1.7.0-openjdk.i386 icedtea-web.i386
Then follow the rest of the Ubuntu instructions
I don’t want Java in my Browser!
Neither do I to be honest. I have the plugin disabled most of the time and enable it only when I want to connect to the VPN.
The version of the client which Juniper distribute as an rpm appears to be a packaged version of the java client which you can load from the browser as described above.
As yet, I’ve not had a chance to do any testing of the rpm version. Details of that will follow in later posts…
I don’t want Java at all!
As far as I can tell, Java is only required for the GUI. It’s a wrapper around a 32bit binary executable which could be called from the command line (or wrapped in a non-java GUI or script I suppose)
I haven’t managed to find the right magic incantation to get it to actually build a VPN tunnel yet, but this is where I’ve got to so far:
- Download the java applet by going to https://uobnet.bris.ac.uk/dana-cached/nc/ncLinuxApp.jar If it asks you to log in, do so using your UoB username and password
- Unpack the archive with
unzip ncLinuxApp.jar
- That should give you a folder full of files, which we need to go into:
cd ncLinuxApp
- There’s a helper script we need to run first, which grabs the SSL certificate in use by the VPN connection. Run it like this:
bash ./getx509certificate.sh uobnet.bris.ac.uk uobnet.crt
- The binary which actually builds the tunnel is “ncsvc” which is a 32bit executable. It appears to require 3 packages on Ubuntu:
sudo apt-get install libc6-i386 lib32z1 lib32nss-mdns
However, at that point I’m stuck. It looks very much like you should be able to build a tunnel by making ncsvc setuid and then calling it with the appropriate parameters:
sudo chown root ncsvc
sudo chmod +s ncsvc
...
Unfortunately I can’t make it work
I’ve made it work! See this followup blog post for details.
I don’t like closed source binaries either..
As Ian has mentioned previously, We’ve not managed to get the network-manager-vpnc client to connect at all. We’ll probably come back to that after prodding at rpms, but in the mean time, if you manage to make it work please let us know!
Further Reading
Most of the above is information culled from the following links. They may be helpful if you fancy having a prod at this yourself.
Some of those links contain perl script wrappers for ncsvc, but as I’ve not had a chance to read every line of that code to make sure it’s not malicious in any way I really can’t recommend you use them!

