Background
Continuous Integration (CI) refers to the concept of automatically testing, building and deploying code as often as possible. This concept has been around in the world of software development for some time now, but it’s new to sysadmins like me.
While the deliverables produced by developers might be more tangible (a mobile app, a website, etc), with the rise of infrastructure as code, sysadmins and network admins are increasingly describing the state of their systems as code in a configuration management system. This is great, as it enables massive automation and scaling. It also opens the door for a more development-like workflow, including some of the tools and knowledge used by developers.
This article describes our progress using a CI workflow to save time, improve quality and reduce risk with our day-to-day infrastructure operations.
Testing, testing…
The Wireless team have used the Puppet configuration management system for several years, for managing server infrastructure, deploying applications and the suchlike. We keep our code in GitLab and do our best to follow best practice when branching/merging. However, one thing we don’t do is automatic testing. When a branch is ready for merging we test manually by moving a test server into that Puppet environment, and seeing if it works properly.
GitLab CI
The IT Services GitLab server at git.services.bristol.ac.uk now provides the GitLab CI service, which at its simplest is a thing that executes a script against your repository to check some properties of it. I thought I would start off simple and write some CI tests to be executed against our Puppet repo to do syntax checking. There are already tools that can do the syntax checking (such as puppet-lint), so all I need to do is write a CI test that executes them.
There’s a snag, though. What is going to execute these tests, and where? How are we going to ensure the execution environment is suitable?
GitLab CI runs on the GitLab server itself, but it executes CI tests in CI runners. Runners can be hosted on the GitLab server, on a different server or in the cloud. To start off simple, I created a new VM to host a single CI runner. So far so good, but the simplest possible runner configuration simply executes the CI tests in a shell on the system it is running on. Security concerns aside, this is also a bad idea because the only environment available is the one the runner is hosted on, and what if a CI test changes the state of the environment? Will the second test execute in the same way?
Docker
This is where Docker steps in. Docker is a container platform which has the ability to create and destroy lightweight, yet self-contained containers on demand. To the uninitiated, you could kind-of, sort-of think of Docker containers as VMs. GitLab CI can make use of Docker containers to execute CI tests. Each CI test is executed in a factory-fresh Docker container which is destroyed after the test has completed, so you can be sure of consistent testing, and it doesn’t matter if you accidentally break the container. The user can specify which Docker image to use for each test.
A real example
So far, this is all talk. Let me show you the components of the simple CI tests I’ve written for our Puppet control repo.
The CI config itself is stored in the root of your git repo, in a file called.gitlab-ci.yml. The presence of this file magically enables CI pipelines in your project. The file tells GitLab CI how to find a runner, which Docker image to use and what tests to execute. Let’s have a look at the config file we’re using for our Puppet repo:
# Docker image to use for these tests
image: git.services.bristol.ac.uk:4567/resnet/netops-ci:master
# Different stages in which to run tests. Only proceed to the
# next stage if the current one passes
stages:
# check: syntax checking
- check
# style: linting
- style
# Check Puppet syntax
puppet-parser:
stage: check
script:
- tests/check-puppet-parser.sh
only:
- branches
# Check ERB template syntax
check-erb:
stage: check
script:
- tests/check-erb.sh
only:
- branches
# Check YAML (Hiera) syntax
check-yaml:
stage: check
script:
- tests/check-yaml.sh
only:
- branches
# Check Puppet linting style
puppet-lint:
stage: style
script:
- tests/style-puppet-lint.sh
only:
- branches
All of the tests are executed in the same way: by calling shell scripts that are in the tests subdirectory of the repo. They have been sorted into two stages – after all, there’s no point in proceeding to run style checks if the syntax isn’t valid. Each one of these tests runs in its own Docker container without fear of contamination.
To give an idea of how simple these CI test scripts are, here’s the one we use to check Puppet syntax – it’s just a one-liner that finds all Puppet manifests in the repo and executes puppet parser validate against each one:
#!/bin/bash
set -euo pipefail
find . -type f -name '*.pp' -print0 | xargs -0 /opt/puppetlabs/bin/puppet parser validate
How CI fits with our workflow
In the configuration we are using, the test suite is executed against the codebase for every commit on every branch. It can also be configured only to run when tags are created, or only on the master branch, etc. For us, this decision is a reflection that we are using an interpreted language, there is no “build” stage and that every branch in the repo becomes a live Puppet environment.
The tests are always run in the background and if they succeed, you get a little green tick at various places throughout the GitLab interface to show you that your commit, branch or merge request is passing (has passed the most recent test).
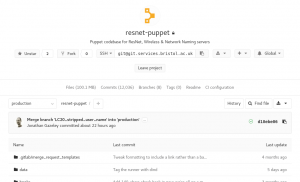
Project summary showing CI status OK
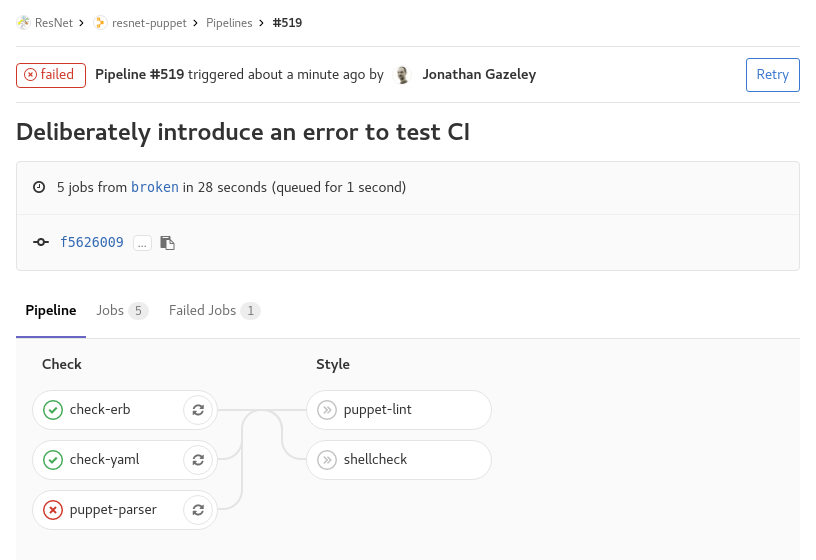
If, however, you push a bad commit that fails testing then you get an email, and all the green ticks turn to red crosses. You can drill down into the failed pipeline, see which specific tests failed, and what errors they returned.
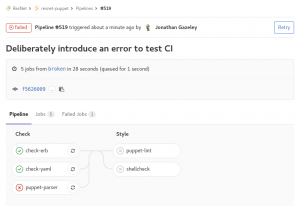
Failed tests
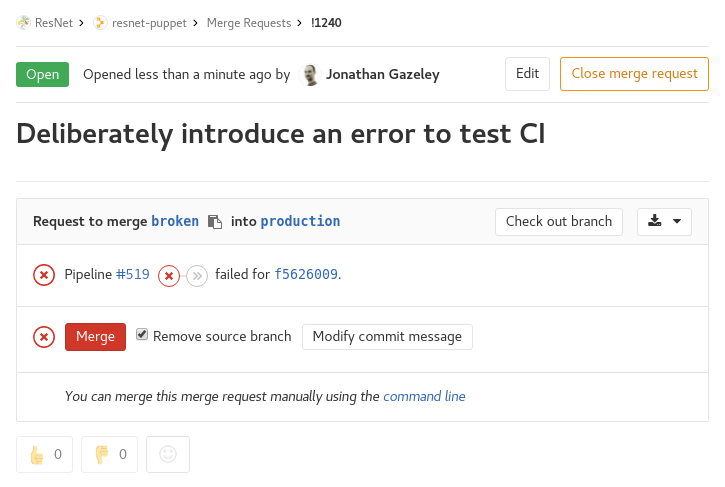
If you carry on regardless and create a merge request for a branch that is failing tests, it won’t let you accept that merge request without a dire warning.
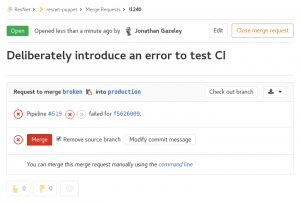
Merge request which failed CI tests
Combining the CI pipeline with setting your master or production branch to be a protected branch means it should be impossible to merge code that has syntax errors. Pretty cool, and a great way of decreasing risk when merging code to production.
I want to play!
Hopefully this article has shown how easy it is to get started running basic CI tests on GitLab CI with Docker. To make things even easier, I have created a repository of sample GitLab CI configs and tests. Have a wander over to the gitlab-ci repo and look at the examples I’ve shared. At the time of writing, there are are configs and tests suitable for doing syntax checks on Puppet configs, Perl/Python/Ruby/Shell scripts and Dockerfiles.
The repo is open to all IT Services staff to read and contribute to, so please do share back any useful configs and tests you come up with.
N.B At the time of writing, the GitLab CI service is provided by a small VM as a proof of concept so tests may be slow if too many people jump on this cool bandwagon. We are in the process of acquiring some better hardware to host CI runners.
As ever, we recommend all GitLab users join the #gitlab-users channel on Slack for informal support and service notifications.
Looking ahead
These CI tests are a simple example of using Docker containers to execute trivial tests and return nothing but an error code. In the future we will be looking to create more complex CI pipelines, including:
- Functional tests, which actually attempt to execute the code and make sure it works as designed rather than just checking the syntax
- Tests that return artefacts, such as a pipeline that returns RPMs after running rpmbuild to build them
- Tests that deploy the end product to a live environment after testing it, rather than just telling a human operator that it’s safe to deploy